Best AI Ad Tools for Creative Analysis You Need Now
AI Ad Creative Analysis · 2026 7 Best AI Ad Tools for Creative Analysis That Are Changing Commercial Video Production […]
The Best AI Video Generators
Hey there, content creators and digital dreamers! Are you tired of spending hours editing footage or struggling to come up with fresh video ideas?
Sign Up VidAU FreeAI Ad Creative Analysis · 2026 7 Best AI Ad Tools for Creative Analysis That Are Changing Commercial Video Production […]

Ad Creative Strategy · 2026 How to Create High-Converting Ad Creatives in Seconds Using AI Learn how to create high-converting

How I Generated $250k Revenue Converting Product Photos Into AI Videos: Complete Technical Workflow for E-commerce I made $250k turning

Amazon Product Review Videos: The Trending Curation Strategy That Generated 35K Views The Algorithmic Death Trap of Generic Product Review

Google Pomelli Update 2026: 5 Game-Changing Features for AI Video Creators Google Pomelli just got a serious upgrade, and if
The Best Unrestricted 18 AI Video Generator in 2026 AI video tools are moving fast. Many creators now search for
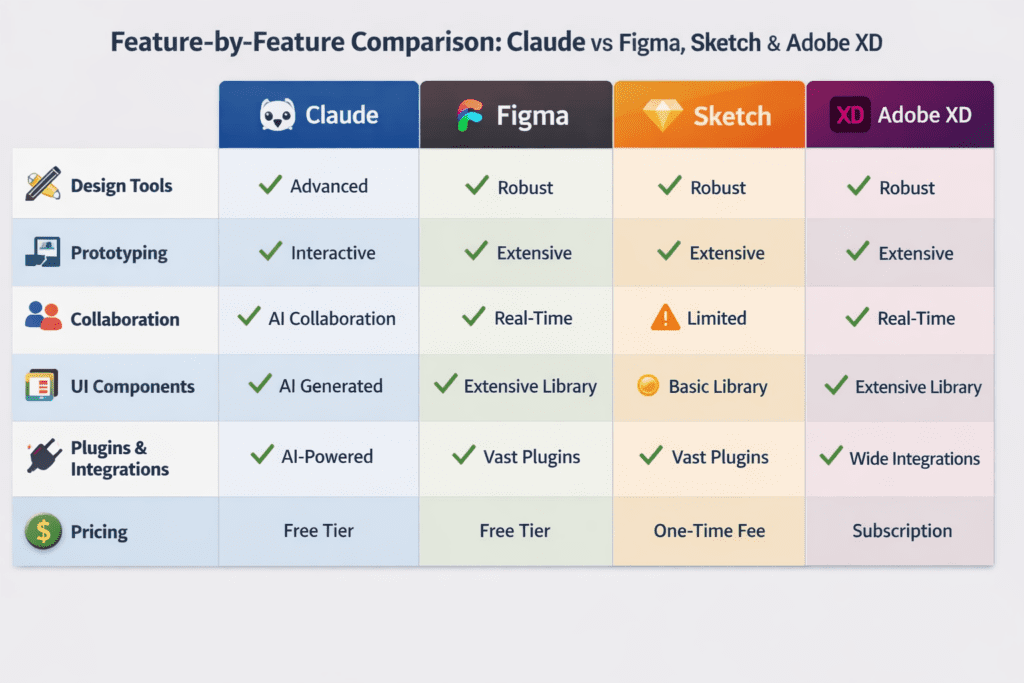
Claude’s Visual Builder vs Paid Design Tools: Complete 2026 Feature Comparison for Developers This Free Claude Feature Just Killed Your

Running Local LLMs: Complete Guide to Private AI Assistants with RAG and Quantization for 2026 Running AI Assistants Locally: Privacy

From Zero to Profitable AI Business: The 2026 Playbook for Building, Launching, and Scaling with Generative Video The complete playbook

AI Biomechanical Analysis Reveals Hidden Details in 1967 Patterson-Gimlin Bigfoot Film That Humans Couldn’t Detect After 57 years of debate,

AI Pattern Recognition in Cryptozoology: Machine Learning Analysis of 100 Years of Bigfoot Sightings Reveals Unsettling Patterns What happens when